共有フォルダと Git を使ったコード管理: 初期設定
ファイルサーバ上の共有ディレクトリに Gitの共有ディレクトリを作成し、そこを使ってコードを管理する場合に行った手順をメモしておきます。
なお、まだ運用を開始していないので、あとで、あれ必要だったーってなるかも。
こんな感じで運用したいです。
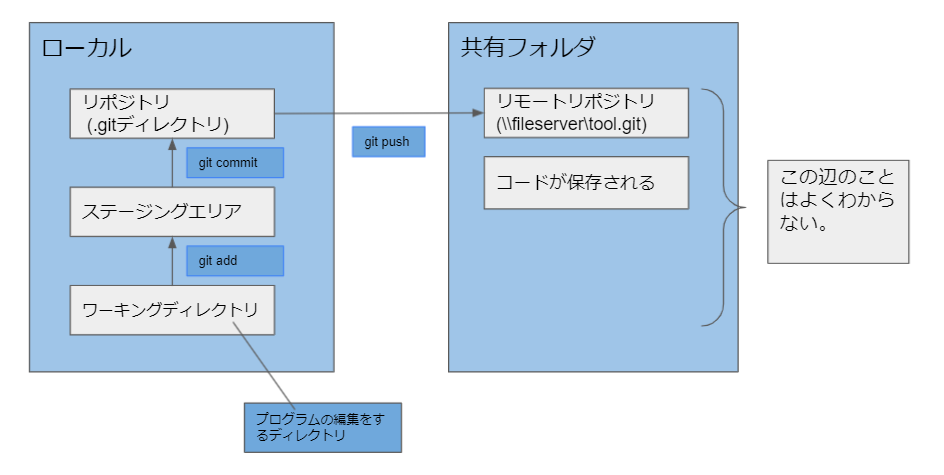
手順概要
手順としては、大まかに言って、共有フォルダ上での初期設定とローカルでの設定の 2つがあります。
始めに共有フォルダ上で共有リポジトリとしての初期化設定をします。
次にローカルのリポジトリを作成し、そこから管理対象となるコードを共有リポジトリへ push します。
1. 共有フォルダ上の初期設定
共有フォルダは、他のマシンからの push を受け付けられるようにベアレポジトリとして構成します。
1. 共有フォルダを準備します。ここではフォルダ名を "tool.git" とします。
ベアリポジトリは一般的に "~.git" という名称を付ける慣習になっているそうです。
```
git init --bare
```
2. ローカルでの設定
ローカルでは、リポジトリ用ディレクトリを準備し、必要なファイルを push します。
1. リポジトリ用ディレクトリを作成します。ここでは、"C:\git\myrepo\" とします。
```
mkdir C:\git\myrepo
```
2. git のリポジトリとして初期化します。
```
cd C:\git\mytrepo
git init
```
3. ファイルサーバの共有リポジトリをクローンします。
以下のコマンドを実行すると、"warning: You appear to have cloned an empty repository." という風に空のリポジトリをクローンしているという警告が表示されますが、とりあえず気にしません。
"git clone" を実行すると、カレントディレクトリに "tool" フォルダが生成されます。(共有リポジトリの "tool.git" から ".git" を除いた名称でディレクトリが作成されるということなのだろうか)
```
git clone \\fileserver\tool.git
cd .\tool
```
4. 管理したいコードを共有リポジトリへ push します。
"tool" に git で管理したいコードをコピーして、共有リポジトリへ push すれば準備完了です。
```
<管理したいファイルを toolディレクトリにコピーします>
git add .
git commit -m "Add tool source files"
git push
```
Git のコマンド1
# Git のコマンド1
## 分散型の性質
Git の分散型という性質の主な利点は何ですか?
1. Git により、複数のリモート作成者からの保存された変更が 1 つのプロジェクト リポジトリに自動的にマージされる。
2. 複数のリモート共同作成者は、互いの作業を上書きする心配なく、プロジェクトで共同作業を行うことができる。 共同作成者は、別の共同作成者からの変更を確認してから、自身のものにマージすることができる。
3. Git では、ファイルおよびフォルダー構造を、安全に維持するためにワイドエリア ネットワークを介して各共同作成者のコンピューターに分散させる。 このアーキテクチャにより、非常に安全なデータ ストレージが提供され、プロジェクト リポジトリのデータが壊れないことが保証される。
### 解説
Ans. "2. 複数のリモート共同作成者は、互いの作業を上書きする心配なく、プロジェクトで共同作業を行うことができる。 共同作成者は、別の共同作成者からの変更を確認してから、自身のものにマージすることができる。"
Git の分散型という性質は、すべての共同作成者がプロジェクト コンテンツの有効性を保証し、維持するのに役立ちます。"
---
##
Git ユーザーがリポジトリをコピーするときに、Git で元のリポジトリに対して設定される参照について説明する用語は何ですか?
1. オリジン
2. リポジトリ
3. リモート
### 解説
Ans. "3. リモート"
リポジトリをクローン (コピー) すると、Git によって "リモート" と呼ばれる元のリポジトリへの参照が作成されます。
Git では "origin" という名前を使用して、リモート リポジトリを参照します。
1: 不正解です。 Git では、origin という名前を使用して元のリポジトリを参照しますが、それは参照自体ではありません。
---
## リポジトリのコピーをするコマンド
既存のリポジトリのコピーを作成する Git コマンドは何ですか?
1. git clone <repo-name>
2. git clone <repo-path>
3. git copy <repo-name>
### 解説
Ans. 2. git clone <repo-path>
git clone コマンドでは、既存のリポジトリへの URL またはパスをパラメーターとして受け取ります。
---
## 現在の変更の保存
現在の変更を保存するために使用できるものの、pull request を使用しない Git コマンドは何ですか?
1. git stash
2. git save
3. git store
### 解説
Ans. "1. git stash"
git stash コマンドでは、いくつかの一時的なコミットを行うことによって、作業ツリーとインデックスの状態を保存します。 この種の保存プロセスは、リポジトリの履歴には影響しません。
---
## 特定のファイルのみをコミットする
リポジトリのローカルの作業ブランチに 10 個のファイルが含まれるプロジェクトがあるとします。 あなたは最近、toc.yml、intro.txt、および exercise.js という 3 つのファイルを更新しました。 ここで、JSON ファイルへの変更に対してのみ pull request を作成する必要があります。 これらの変更に対してのみ pull request を作成するために使用する必要がある Git コマンドのセットは何ですか?
1. "git add ." を使う
+ git add .
+ git commit -m "my changes for the exercise"
+ git push origin <working-branch>
2. "git add exercise.json" を使う
+ git add exercise.json
+ git commit -m "my changes for the exercise"
+ git push origin <working-branch>
3. "git add exercise" を使う
+ git add exercise
+ git commit -m "my changes for the exercise"
+ git push remote <working-branch>
### 解説
Ans. "2. git add exercise.json" を使う
現在のすべての変更をプッシュするには、git add の後に . を指定します。 1 つのファイルに対してのみ変更をプッシュするには、特定のファイル名を入力します。
3: git add およびgit push コマンドの構文を確認してください。 git add コマンドの場合は、必ず、拡張子の種類 (exercise.json) で完全なファイル名を指定してください。 git push コマンドの場合は、参照 (remote) ではなく、リモート (origin) の名前を指定します。
Git の概要
# Git の概要
## 次のシナリオのうち、バージョン コントロール システムの一般的なユース ケースはどれですか?
1. 最新のファイルまたはデータだけを操作していることが確実になるように、以前のバージョンのプロジェクトまたはファイルを削除する。
2. 分離されたブランチ内のプロジェクトに試験的な変更を加える。
3. 大規模なプロジェクトの機能要件を収集し、それらを関係者に伝える。
### 解説
Ans. "2. 分離されたブランチ内のプロジェクトに試験的な変更を加える。"
"1": バージョン コントロール システムでは、以前のバージョンのプロジェクトまたはファイルに必要に応じてアクセスできるように、これらを意図的に保持しています。
---
## バージョン コントロール システムのもう 1 つの名前は何ですか?
1. バージョン管理ソフトウェア (VMS)
2. ソフトウェア コントロール管理 (SCM) システム
3. ソフトウェア構成管理 (SCM) システム
### 解説
Ans: 3. ソフトウェア構成管理 (SCM) システム
## Git と GitHub の違いは何ですか?
1. Git を使用すると、1 つ以上のローカル ブランチを操作し、それらをリモート リポジトリにプッシュできます。 GitHub はリモート リポジトリとして機能し、Web サイトまたはコマンド ライン ツールを通じてアクセスされます。
2. Git は、クラウドで実行される分散型バージョン コントロール システム (DVCS) です。 GitHub は、Git テクノロジへのアクセスを提供するインターフェイス レイヤーです。
3. Git は、個々の共同作成者によって使用されます。 GitHub は、グループ開発作業を簡素化するために複数の共同作成者によって使用されます。
### 解説
Ans. "1. Git を使用すると、1 つ以上のローカル ブランチを操作し、それらをリモート リポジトリにプッシュできます。 GitHub はリモート リポジトリとして機能し、Web サイトまたはコマンド ライン ツールを通じてアクセスされます。"
"2": ユーザーは Git と GitHub の両方にアクセスできます。 GitHub は、Git DVCS を使用したクラウド プラットフォームです。
---
## Git コマンド
Gitの使用方法に関する情報を提供する Git コマンドはどれですか?
1. git init
2. git status
3. git help
### 解説
Ans. "3. git help"
"2": git status コマンドを使用すると、Git によって現在追跡されている変更を確認できます。
---
## Git コマンド
間違いを修正するには、どの Git コマンドを使用できますか?
1. git reset と git recover
2. git reset および git revert
3. git revert と git remove
### 解説
Ans. "2. git reset および git revert"
git reset および git revert を使用して、Git で間違いを回復および修正できます。
ログデータや冗長性などに関する問題集
## Azure Sentinel と Azure Security Center の基盤として共有されるログデータ
Azure Sentinel と Azure Security Center で基盤として共有されているログ データ プラットフォームは何ですか。
1. 診断設定
2. Azure Monitor ログ
3. アクティビティ ログ
### Explanation
Ans: "2. Azure Monitor ログ"
Sentinel や Security Center を含む Azure のいくつかのサービスでは、基になる ログ データ プラットフォームとして Azure Monitor ログを使用します。
"1": 診断設定は、プラットフォームのメトリックとプラットフォームのログを Azure Monitor Log Analytics、ストレージ アカウント、または Event Hubs に送信するために使用されます。
"3": アクティビティ ログは、Azure プラットフォームのログであり、サブスクリプションレベルのイベントの分析情報が提供されます。
---
## geo 冗長構成をとる場合に別のリージョンに明示的にコピーする必要があるリソース
geo 冗長構成をとる場合に、別のリージョンに明示的にコピーする必要がありますか?
1. Azure DNS と Azure AD
2. Azure App Service、Azure 関数アプリ、Redis Cache、キュー
3. Azure DNS、Azure AD、Azure Storage
### Explanation
Ans: "2. Azure App Service、Azure 関数アプリ、Redis Cache、キュー"
これらのコンポーネントは、明示的にコピーするか、別のリージョンにレプリケートする必要があります。
"3": Azure DNS と Azure AD はどちらも既定でマルチリージョンなので、コピーする必要はありません。 Azure Storage は、コピーするのではなく、複数のリージョンに存在するように構成します。
---
## Azure Storage の geo冗長
次の文章を完成させてください。Azure Storage でリージョン規模の障害が発生した場合、データの損失は...
1. すべてのデータがセカンダリ リージョンに自動的にコピーされるため、発生しない。
2. データが非同期的にコピーされるため、短時間について発生する可能性がある。
3. 短時間発生する可能性があるが、マスターからデータを復元できる
### Explanation
Ans: "2. データが非同期的にコピーされるため、短時間について発生する可能性がある。"
RA-GRS では、データがプライマリからセカンダリに非同期的にコピーされるため、データが失われる可能性があります。
"1": 適切な構成では、データはコピーされますが、この操作は非同期的に行われるため、データが失われる可能性があります。
---
## スタンバイリージョンに明示的にコピーする必要があるリソース
リージョン規模の障害が発生した場合に、SQL データベースへの書き込みアクセスを自動的にフェールオーバーする必要があります。 カスタム コードを記述したくはありません。 何をする必要がありますか?
1. アクティブ geo レプリケーションを使用する
2. 自動フェールオーバー グループを使用する
3. 複数書き込みリージョンを使用する
### Explanation
Ans: "2. 自動フェールオーバー グループを使用する"
自動フェールオーバー グループを使用することにより、セカンダリ リージョンのレプリカに自動的にフェールオーバーするようにプライマリ データベースを構成できます。
---
## リージョン規模の障害発生時に完全にデータを保護するには ?
リージョン規模の障害時に、完了したトランザクションが 1 つも失われないようにする必要があります。 何をする必要がありますか?
1. 1 つの書き込みリージョンで Azure Cosmos DB を使用する。
2. アクティブ geo レプリケーションで Azure SQL Database を使用する。
3. 自動フェールオーバー グループで Azure SQL Database を使用する。
### Explanation
Ans: "1. 1 つの書き込みリージョンで Azure Cosmos DB を使用する。"
Azure Cosmos DB では同期レプリケーションが使用されており、トランザクションはレプリカのクォーラムにレプリケートされたときにのみ完了します。
---
## 自動スケーリングとは ?
自動スケーリングについての最も適切な説明はどれですか?
1. 自動スケーリングは、スケールアップ/スケールダウン ソリューションです。 需要が多い期間中はより強力なハードウェアにアプリケーションを移行し、需要が少なくなったら性能の低いハードウェアに戻します。
2. 自動スケーリングでは、管理者がシステム上のワークロードを積極的に監視する必要があります。 ワークロードが増えて応答時間が低下し始めた場合、管理者は自動スケーリングをトリガーし、システムのスループットを増やすことができます。
3. 自動スケーリングは、スケールアウト/スケールイン ソリューションです。 システムは、指定されたリソースのメトリックで使用量の増加が示されるとスケールアウトし、これらのメトリックが低下するとスケールインできます。
4. 自動スケーリングは、数分間継続するアクティビティの突然の急増を処理するのに理想的なソリューションです。
5. スケールインとスケールアウトでは、自動スケーリングより優れた可用性が提供されます。
### Explanation
Ans: "3. 自動スケーリングは、スケールアウト/スケールイン ソリューションです。 システムは、指定されたリソースのメトリックで使用量の増加が示されるとスケールアウトし、これらのメトリックが低下するとスケールインできます。"
"4": 自動スケーリングでは、リソースを追加するのに時間がかかります。 システムが追加リソースを起動する前に、アクティビティの急激な増加が終わってしまう可能性があります。
---
## 自動スケーリングとワークロードの関係
自動スケーリングを使用すると、システムはワークロードの増加を処理するために必要なリソースを予測できます。
1. 正しい
2. 正しくない
### Explanation
Ans: "2. 正しくない"
---
## 自動スケーリングをいつ使うのか ?
次のシナリオのうち、自動スケーリングに適している候補はどれですか?
1. アプリケーションへのアクセスを必要とするユーザーの数が、定期的なスケジュールに従って変化します。 たとえば、金曜日には他の曜日よりシステムを使用するユーザーが増えます。
2. 要求が急増して、システムが停止する可能性があります。 ワークロードは指数関数的に増加しており、このアクティビティの急増には理由がないように見えます。
3. 時間の経過と共に、サービスの人気が高くなっており、増加するトラフィックを処理する必要があります。
4. 組織はキャンペーンを実施しており、次の 2 週間は Web サイトへのトラフィックが増加すると予想されます。 キャンペーンの開始時に、予想される需要を処理するのに十分なリソースを使用できることを確認します。
### Explanation
Ans: "1. アプリケーションへのアクセスを必要とするユーザーの数が、定期的なスケジュールに従って変化します。 たとえば、金曜日には他の曜日よりシステムを使用するユーザーが増えます。"
スケジュールに従って実行するように自動スケーリングを構成することもできます。
"2": アクティビティの急増は、システムを過負荷にしようとするサービス拒否攻撃が原因であると考えられます。 自動スケーリングでは、問題は解決されません。 これらの要求がシステムをホストするサーバーに到達する前に、セキュリティ インフラストラクチャを使用して要求をフィルター処理します。
"3": このシナリオでは、おそらく手動スケーリングの方がより適切なオプションです。 需要は、長期間にわたって増え続けています。
"4": キャンペーンが開始する前にシステムを手動でスケーリングし、アクティビティを監視して、キャンペーンが終了したら元に戻します。
---
## 自動スケーリングルールに関する質問1
4 つの自動スケーリング ルールで自動スケーリング条件を定義しました。 1 番目のルールでは、CPU 使用率が 70% に達するとスケールアウトします。 2 番目のルールでは、CPU 使用率が 50% を下回ると元にスケールインします。 3 番目のルールでは、メモリの占有率が 75% を超えるとスケールアウトします。 4 番目のルールでは、メモリの占有率が 50% 未満になると元にスケールインします。 システムがスケールアウトするのは次のどのときですか?
1. CPU 使用率が 70% に達したとき、または、メモリの占有率が 75% を超えたとき
2. CPU 使用率が 70% に達したとき、かつ、メモリの占有率が 75% を超えたとき
3. 1 つの自動スケーリング条件で、これを行うことはできません。 1 つの自動スケーリング条件に含めることができるのは、同じメトリックを使用する自動スケーリング ルールだけです
### Explanation
Ans: "1. CPU 使用率が 70% に達したとき、または、メモリの占有率が 75% を超えたとき"
スケールアウトするかどうかを決定するときは、スケールアウト ルールの いずれか が満たされた場合に自動スケーリング アクションが実行されます。
スケールインのときは、スケールイン ルールの すべてが満たされた場合にのみ、自動スケーリング アクションが実行されます。
---
## 自動スケーリング動作2
自動スケーリング ルールでは、ディスク キューの長さが 10 を超えるとインスタンスの数を増やすスケールアウト アクションが定義されています。 システムは 2 分前にスケールアウトしましたが、ディスク キューの長さはまだ 10 を超えています。 システムが再びスケールアウトするのは次のどのときですか?
1. 自動スケーリング ルールではすぐに別の自動スケーリング アクションがトリガーされ、ディスク キューの長さが 10 未満になるか、最大数のインスタンスが作成されるまで、それが続けられます。
2. 自動スケーリング ルールは、システムがスケールインして戻るまで、再び実行されることはありません。
3. 自動スケーリング ルールでは、ルールに対する "クール ダウン" 期間が経過するまで、再度アクションがトリガーされることはありません。 その時点でディスク キューの長さがまだ 10 を超えている場合は、アクションが実行されます。
### Explanation
Ans: "3. 自動スケーリング ルールでは、ルールに対する "クール ダウン" 期間が経過するまで、再度アクションがトリガーされることはありません。 その時点でディスク キューの長さがまだ 10 を超えている場合は、アクションが実行されます。"
---
## Cosmos DB の RU
正誤問題:同じデータに対する特定のデータベース操作に使用される RU の数は、時間の経過と共に変わります。
1. 正
2. 誤り
### Explanation
Ans: "2. 誤り"
Azure Cosmos DB では、特定のデータセットに対する特定のデータベース操作の RU の数が確実に決定的になります。
---
## Cosmos DB の RU数は何に基づいて変化するのか ?
ドキュメントの書き込みに使用する要求ユニット数に影響するのは、次のうちどれですか?
1. ドキュメントのサイズ
2. アイテム プロパティの数
3. インデックス作成ポリシー
4. 上記のすべて
### Explanation
Ans: "4. 上記のすべて"
要求ユニットをプロビジョニングするとき、3 つのオプション (ドキュメントのサイズ、アイテム プロパティの数、インデックス作成ポリシー) のすべてが考慮されます。
---
## RU の性質
Azure Cosmos DB の要求ユニット (RU) に関する次の記述のうち、誤っているものはどれですか?
1. 1 KB のアイテムを読み取るのにかかるコストは約 1 要求ユニット (つまり 1 RU) です。
2. プロビジョニングされた RU の数を超えた場合、要求は速度制限されます。
3. 要求ユニットの数を設定したら、この数を変更することはできません。
4. Azure Cosmos コンテナー (またはデータベース) 上で 'R' 個の RU をプロビジョニングした場合、Azure Cosmos DB では、ご利用のアカウントに関連付けられた各リージョンで 'R' 個の RU が確実に利用できるようになります。
s
### Explanation
Ans: "3. 要求ユニットの数を設定したら、この数を変更することはできません。"
コンテナーまたはデータベースにプロビジョニングされた要求ユニットの数は増減することができます。
---
## Azure Cosmos DB コンテナーの作成後に、パーティション キーを 追加できるのか ?
正誤問題: Azure Cosmos DB コンテナーの作成後に、パーティション キーを 追加 できます。
1. 正しい
2. いいえ
### Explanation
Ans: "2. いいえ"
パーティション キーは、コンテナーの作成時にのみ設定できます。
---
## パーティションキーの選び方
組織では、1 秒ごとに数百万の車両から生成される車両テレメトリ データを格納するために、Azure Cosmos DB を使用することを計画しています。 ストレージの分散を最適化するパーティション キーのオプションは次のうちどれですか?
1. 車両モデル
2. WDDEJ9EB6DA032037 のような車両識別番号 (VIN)
### Explanation
Ans: "2. WDDEJ9EB6DA032037 のような車両識別番号 (VIN)"
自動車製造元では、1 年を通してトランザクションが発生しています。 このオプションでは、パーティション キー値の間でよりバランスのとれたストレージの分散が行われます。
"2": ほとんどの自動車製造元には、数十のモデルしかありません。 このオプションは最も大まかなものである可能性があり、一定数の論理パーティションが作成され、すべての物理パーティション間で均等にデータが分散されない場合があります。
Azure File Syncのセットアップ
# Azure File Syncのセットアップ
## Azure File Sync の設定
1. オンプレミスのファイルサーバの互換性を評価する
オンプレミス サーバーで評価用のコマンドレットを実行し、OS とファイル システムがサポートされているかどうかを確認します。
2. Azure リソースを作成する
ストレージ アカウントを作成し、ストレージ アカウント内にファイル共有を作成します。そして、ストレージ同期サービスを作成し、ストレージ同期サービ
ス内に同期グループを作成します。
同期グループを作成すると、同期グループにクラウドエンドポイントが作成されます。
3. オンプレミスのファイルサーバに Azure File Sync エージェントをインストールする
ストレージ同期サービスへのレプリケーションに参加する各ファイル サーバーにエージェントをインストールします。
4. Windows Server コンピューターをストレージ同期サービスに登録する
ファイルサーバに同期エージェントをインストールすると、同期エージェントのダイアログ上で、サーバーをストレージ同期サービスに登録するように求められます。
5. サーバー エンドポイントを作成する
Azure Portal で同期グループにエンドポイントを追加します。
### 1. オンプレミスのファイルサーバの互換性を評価する
ファイルサーバ上で、Azure PowerShell モジュールをサーバーにインストールし、Invoke-AzStorageSyncCompatibilityCheck コマンドレットを使用します。
### 2. Azure リソースを作成する
1.ストレージ アカウント
ストレージ アカウントは、ファイル共有を格納するために使用されます。
ホット アクセス層がある StorageV2 を選択します。
2. ファイル共有
クォータ サイズを指定して、ファイル共有のサイズを制御します。 必要に応じて、後でクォータを増やすことができます。
3. ストレージ同期サービス
ストレージ同期サービスは、会社のサーバーと Azure 間の信頼を確立する役割を担います。 このサービスで、Azure のファイル共有をサーバーのファイル
ディレクトリに接続します。
Azure Portal 上の名称は、"Azure ファイル同期" または、Azure File Sync です。"ストレージ同期サービス" はビューを表示します。
4. 同期グループ
同期グループには、Azure ファイル共有を表す 1 つのクラウド エンドポイントと、登録済みの Windows ファイル サーバー上のパスにマップされる 1 つ以上
のサーバー エンドポイントが含まれている必要があります。 同期グループでは、非表示のフォルダー .SystemShareInformation に格納されている
メタデータを使用してプロセスを管理します。 このフォルダーは削除しないでください。
同期グループは、ストレージ同期サービスの "概要" から追加します。
---
## クラウド エンドポイントの変更検出ジョブの実行間隔
クラウド エンドポイントの変更検出ジョブは、どのくらいの頻度で実行されますか。
1. 12 時間ごと
2. 8 時間ごと
3. 24 時間ごと
### Explanation
Ans: "24 時間ごと"
---
## Azure File Sync エージェントとは何か
Azure File Sync エージェントとは何ですか。
1. ローカル ファイル共有と Azure ファイル共有の間の Azure File Sync レプリケーションを有効にするために、サーバーにインストールされます。
2. ファイルとフォルダーに対する NTFS アクセス許可を設定するために、サーバーにインストールされます。
3. オンプレミスのファイルとフォルダーのレプリケーション トラフィックを制御するために、Azure ファイル共有にインストールされます。
### Explanation
Ans: "1. ローカル ファイル共有と Azure ファイル共有の間の Azure File Sync レプリケーションを有効にするために、サーバーにインストールされます。"
Azure File Sync エージェントは、Windows Server ファイル共有を Azure ファイル共有と同期できるようにするダウンロード可能なパッケージです。
---
## オンプレミスサーバの評価
サーバーと Azure File Sync の互換性はどのように評価しますか。
1. Azure File Sync エージェントをダウンロードして実行し、ファイル共有とサーバーを評価します。
2. Azure PowerShell モジュールをサーバーにインストールし、Invoke-AzStorageSyncCompatibilityCheck コマンドレットを使用します。
3. サーバーをストレージ同期サービスに登録して、サーバーの互換性を評価します。
### Explanation
Ans: "2. Azure PowerShell モジュールをサーバーにインストールし、Invoke-AzStorageSyncCompatibilityCheck コマンドレットを使用します。"
OS、ファイル システム、ファイル名、またはフォルダー名に互換性の問題があるかどうかが、コマンドレットの結果に示されます。
---
## Azure File Sync をサポートするために必要な Azure リソースの作成順序
Azure File Sync をサポートするために必要な Azure リソースはどの順序で作成しますか。
1. ストレージ同期サービス、ストレージ アカウント、ファイル共有、同期グループ。
2. ストレージ アカウント、ファイル共有、ストレージ同期サービス、同期グループ。
3. ストレージ アカウント、ファイル共有、同期グループ、ストレージ同期サービス。
### Explanation
Ans: "2. ストレージ アカウント、ファイル共有、ストレージ同期サービス、同期グループ"
ストレージ アカウントを作成してから、ストレージ アカウント内にファイル共有を作成します。
そして、ストレージ同期サービスを作成し、ストレージ同期サービス内に同期グループを作成します。
"1": Azure Storage アカウントでストレージ同期サービスを作成します。
"3": 同期グループは、ストレージ同期サービス内に作成されます。
---
## Azure File Sync におけるクラウドを使った階層化
Azure File Sync でのクラウドを使った階層化とは何ですか。
1. ファイル共有の同期順序の優先順位を付けるために作成するポリシーです。
2. 同期ジョブを実行する頻度を設定するポリシーです。
3. アクセス頻度の低いファイルをアーカイブしてローカル ファイル共有の領域を解放する機能です。
### Explanation
Ans: "3. アクセス頻度の低いファイルをアーカイブしてローカル ファイル共有の領域を解放する機能です。"
クラウドを使った階層化により、アクセス頻度の高いファイルをローカル サーバーにキャッシュできます。 アクセス頻度の低いファイルは、作成したポリシーに
従って、Azure ファイル共有に階層化すなわちアーカイブされます。
---
## Azure File Sync のデプロイプロセス
Azure File Sync のデプロイ プロセスはどのようになりますか。
1. オンプレミスのシステムを評価し、Azure リソースを作成し、Azure File Sync エージェントをインストールし、オンプレミス サーバーを登録して、サーバー エンドポイントを作成します。
2. Azure リソースを作成し、Azure File Sync エージェントをインストールし、オンプレミス サーバーを登録して、サーバー エンドポイントを作成します。
3. オンプレミスのシステムを評価し、Azure リソースを作成し、仮想マシンに Azure File Sync エージェントをインストールし、オンプレミス サーバーを登録して、サーバー エンドポイントを作成します。
### Explanation
Ans: "1. オンプレミスのシステムを評価し、Azure リソースを作成し、Azure File Sync エージェントをインストールし、オンプレミス サーバーを登録して、サーバー エンドポイントを作成します。"
1. オンプレミス サーバーの OS とファイル システムがサポートされていることを確認します。
2. 次に、Azure で必要なリソースを作成します。
3. ローカル サーバーで、Azure File Sync エージェントをインストールし、サーバーを登録します。
4. 最後に、Azure でサーバー エンドポイントを作成します。
"2": 最初に、オンプレミスのサーバーを評価して、Azure File Sync で動作することを確認します。
---
## ファイル同期の問題の原因として考えられないもの
ファイル同期の問題の原因として考えられないのは、これらの回答のうちどれですか。
1. 会社のファイアウォール規則により、ポート 445 でのネットワーク トラフィックがブロックされています。
2. ストレージ同期サービスを実行している仮想マシンが停止しています。
3. オンプレミスのサーバーが SMB 暗号化をサポートしていません。
### Explanation
Ans: "2. ストレージ同期サービスを実行している仮想マシンが停止しています。"
"2": ストレージ同期サービスは、Azure File Sync のための高レベルの Azure リソースです。このリソースは Azure で作成します。
"3": Azure は、セキュリティで保護されていない接続を拒否します。
Azure CLI (PowerShell) を使って VM をセットアップする
# Azure CLI (PowerShell) を使って VM をセットアップする
## リソースグループ作成
```commandline
$resourceGroup = 'learn-file-sync-rg'
$location = 'EastUS'
New-AzResourceGroup -Name $resourceGroup -Location $location
```
## サブネットの作成
```commandline
$subnetConfig = New-AzVirtualNetworkSubnetConfig `
-Name Syncpublicnet `
-AddressPrefix 10.0.0.0/24
$virtualNetwork = New-AzVirtualNetwork `
-Name Syncvnet `
-AddressPrefix 10.0.0.0/16 `
-Location $location `
-ResourceGroupName $resourceGroup `
-Subnet $subnetConfig
```
## VM の管理者情報の生成
```commandline
$cred = Get-Credential
```
## VM の作成
```commandline
New-Azvm `
-Name FileServerLocal `
-Credential $cred `
-ResourceGroupName $resourceGroup `
-Size Standard_DS1_v2 `
-VirtualNetworkName Syncvnet `
-SubnetName Syncpublicnet `
-Image "MicrosoftWindowsServer:WindowsServer:2019-Datacenter-with-Containers:latest"
```
Azure CLI (PowerShell) を使って VM をセットアップする
# Azure CLI (PowerShell) を使って VM をセットアップする
## リソースグループ作成
```commandline
$resourceGroup = 'learn-file-sync-rg'
$location = 'EastUS'
New-AzResourceGroup -Name $resourceGroup -Location $location
```
## サブネットの作成
```commandline
$subnetConfig = New-AzVirtualNetworkSubnetConfig `
-Name Syncpublicnet `
-AddressPrefix 10.0.0.0/24
$virtualNetwork = New-AzVirtualNetwork `
-Name Syncvnet `
-AddressPrefix 10.0.0.0/16 `
-Location $location `
-ResourceGroupName $resourceGroup `
-Subnet $subnetConfig
```
## VM の管理者情報の生成
```commandline
$cred = Get-Credential
```
## VM の作成
```commandline
New-Azvm `
-Name FileServerLocal `
-Credential $cred `
-ResourceGroupName $resourceGroup `
-Size Standard_DS1_v2 `
-VirtualNetworkName Syncvnet `
-SubnetName Syncpublicnet `
-Image "MicrosoftWindowsServer:WindowsServer:2019-Datacenter-with-Containers:latest"
```